




Danielle Parsons, The Ohio State University and Bryan Carstens, The Ohio State University
Taxonomy, the study of how living organisms relate to one another as species, has been around since the 1700s. Though scientists and philosophers have long debated what makes a species a species, taxonomists treat each species as a group of organisms that share common biological characteristics.
Discovering and describing new species is essential to biology researchers and conservationists because they use species as a unit of analysis. Species are also economically important to agriculture, hunting and fishing, and have special legal status, such as under the U.S. Endangered Species Act.
Despite this, scientists have been able to formally name and describe only an estimated 10% of species on the planet, based on discovery trends over the years.
This gap in knowledge is known as the Linnean shortfall. It remains unclear whether poor research methodology, disagreements on how to define a species, or other factors are to blame for this gap.
We are scientists in evolutionary biology, and figuring out ways to better identify species is central to our research. Using genetic analysis and artificial intelligence, we were able to disentangle hidden species that have been lumped together in a single group and predict where and what types they might be. Our findings also pinpoint a potential cause for this shortfall in species identification: an underinvestment in the science of taxonomy. https://www.youtube.com/embed/dnfaiJJnzdE?wmode=transparent&start=0 Determining what makes a species can get complicated.
Hidden species remain to be discovered
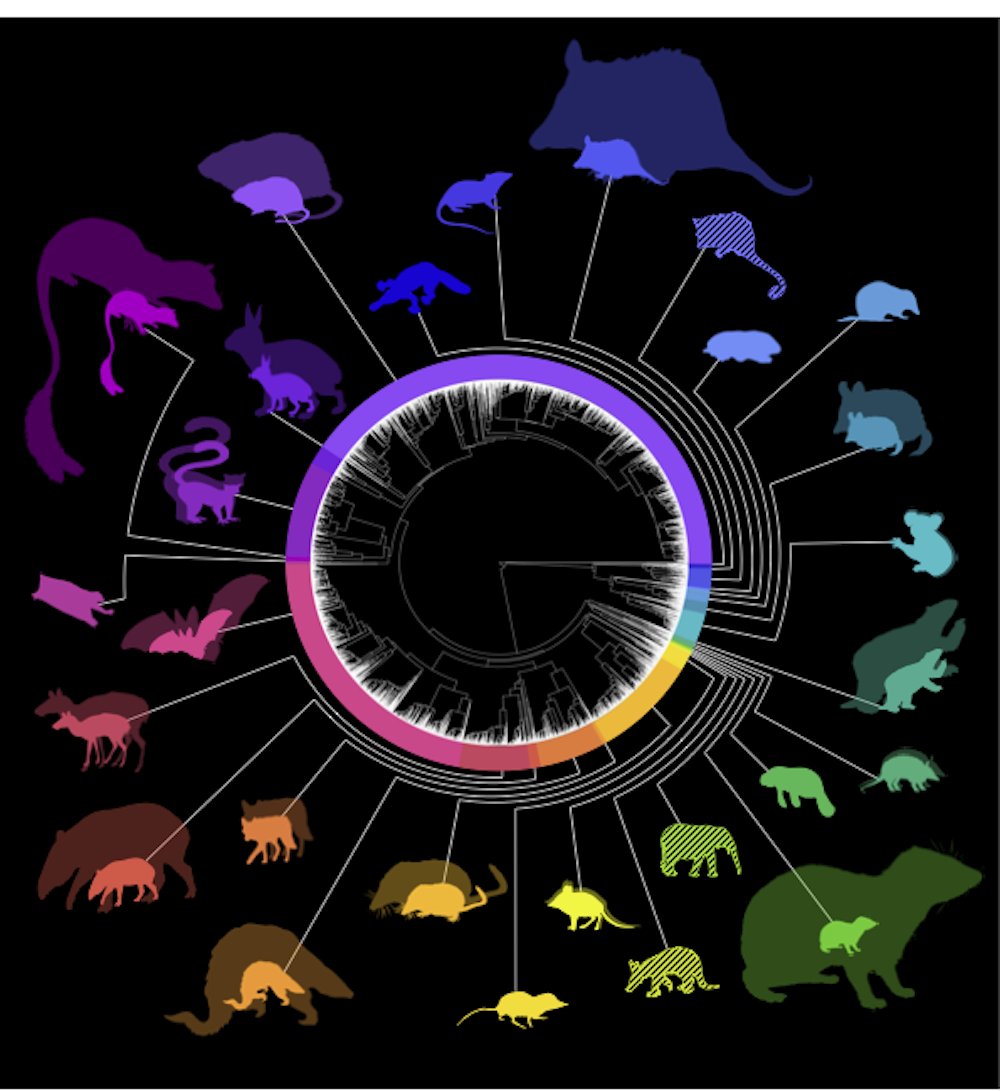
For this study, we chose to focus on mammals. Because of their relatively large size and importance to people as a source of food, companionship and entertainment, we predicted that it was more likely that a large proportion of mammalian species have been already been identified.
Our first task was to identify known species that might actually contain two or more species. To do this, we analyzed 1 million gene sequences from 4,300 named species, identifying clusters of sequences that showed high genetic diversity and fitting the data to an evolutionary model.
We found potentially hundreds of hidden species that were previously classified as a single group. This finding was expected, as it mirrors results from previous studies, albeit on a larger scale.
Where and what are these hidden species?
Once we identified the presence of these potentially hidden species, our second task was to determine what specific traits they have in common. To do this, we used a data science technique called random forest analysis, a form of machine learning that draws information from a large number of different variables in order to make a prediction about a particular outcome. It’s similar to the technique that Netflix uses to suggest shows you might be interested in watching. https://www.youtube.com/embed/cIbj0WuK41w?wmode=transparent&start=0 Random forests is a machine learning algorithm that makes predictions using multiple decision trees.
In our case, we wanted to predict whether a known species contained hidden species. The predictor variables we used spanned environmental factors, such as the climate of common mammalian habitats, and species-specific factors, such as physical traits, geographic range, reproductive and survival patterns. We also included research-based factors on the techniques scientists used to conduct their studies. In total, we collected some 3.8 million data points to build our model.
Based on our model, we found that three types of predictor variables stood out the most.
The first type comprised attributes of the species itself, such as body mass and geographic range. These results suggest that small mammals with relatively large ranges are more likely to have hidden species. This makes sense as, all things being equal, it is more difficult for scientists to recognize physical differences in smaller animals than larger ones.
The second type was climate – there are likely to be more hidden species in wet, warm areas with a large difference in day and night temperatures. This likely reflects the fact that tropical rainforests tend to have very high levels of mammalian diversity.
The third type was research effort, including the geographic dispersion of samples in museum collections and the number of recent publications mentioning the scientific name of a known species. This implies that researchers are generally effective in identifying new mammals, as how much attention the scientific community has focused on a specific mammal predicts whether that creature is identified. This is supported by how the general characteristics we’ve identified match new mammalian species described over the past 30 years, as well as the fact that our model recognizes areas that scientists are already investigating for hidden species.
Unknown species face extinction
At a time when Earth is facing its greatest extinction crisis since an asteroid killed off the dinosaurs, we believe that identifying and describing the many undiscovered species on Earth is crucial to aiding the preservation of its biodiversity.
Even though our study still found a large number of mammals waiting to be discovered, mammalian diversity is already relatively well captured compared with that of other species. We found that roughly 80% of existing mammal species have already been described, a proportion far higher than in nonmammal groups with even higher diversity such as beetles or mites.
Discovering and describing new species, as with all scientific research, takes a village. Natural history museums are largely responsible for collecting the raw data we analyzed, and genetic and biodiversity databases provided the infrastructure to make it accessible to us. A culture of information sharing among peers and large computer networks supported the thousands of hours of computation time we needed. Our work was made possible only by ongoing investments in taxonomic research.
Biodiversity scientists are racing to better understand the processes that create and maintain biodiversity while in the midst of the planet’s sixth mass extinction, one that is entirely caused by human actions. Taxonomists face the challenge of describing the species around us before they go extinct. As our findings suggest, there is still a long way to go.
Danielle Parsons, PhD Candidate in Evolutionary Biology, The Ohio State University and Bryan Carstens, Professor of Evolutionary Biology, The Ohio State University
This article is republished from The Conversation under a Creative Commons license. Read the original article.
















{kind=link}